HDFS分布式文件系统 架构解析与Shell操作实践
一、引言:HDFS在现代计算机网络系统工程中的角色
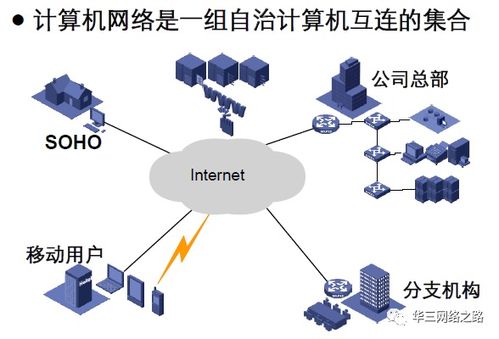
Hadoop分布式文件系统(HDFS)是Apache Hadoop项目的核心组件,设计用于在低成本商用硬件上可靠地存储超大规模数据集。在当今的大数据时代,HDFS已成为企业级数据湖、数据分析平台和机器学习基础设施的基石。它通过将数据分散存储在集群中的多个节点上,提供了高吞吐量的数据访问能力,完美契合了“一次写入、多次读取”的数据处理模式。对于计算机网络系统工程服务而言,深入理解HDFS的架构并熟练掌握其操作,是构建高效、可扩展数据存储与处理平台的关键。
二、HDFS核心架构解析
HDFS采用主从(Master/Slave)架构,主要由以下几个关键组件构成:
- NameNode(主节点):
- 职责:作为集群的“管理者”,负责管理文件系统的命名空间(如目录树、文件元数据)以及协调客户端的访问。它维护着文件到数据块(Block)的映射关系以及数据块在集群中的位置信息。
- 关键特性:其状态信息至关重要,通常通过配置高可用(HA)方案(如使用ZooKeeper和JournalNode)和启用NameNode Federation来避免单点故障并提升扩展性。
- DataNode(从节点):
- 职责:作为“工作者”,负责在本地磁盘上实际存储数据块,并响应来自NameNode和客户端的读写请求。DataNode会定期向NameNode发送心跳信号和数据块报告,以确认其活跃状态和存储内容。
- Secondary NameNode(辅助节点,非热备):
- 注意:其名称容易引起误解,它并非NameNode的热备份。其主要职责是定期合并NameNode的编辑日志(edits)到镜像文件(fsimage),以减少NameNode重启时间并保存检查点。在高可用(HA)部署中,其角色通常被Standby NameNode所取代。
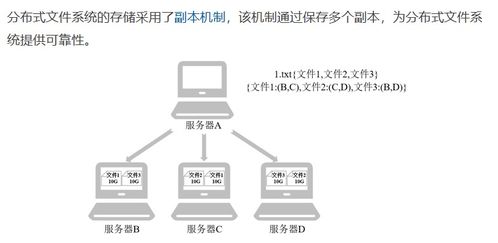
- 数据块(Block)与副本机制:
- HDFS将大文件切分成固定大小的数据块(默认128MB或256MB)进行存储。
- 每个数据块会被复制到多个(默认3个)不同的DataNode上,这种多副本机制是HDFS实现容错性和数据可靠性的核心。即使个别节点发生故障,数据依然可用。
- 写数据与读数据流程:
- 写入:客户端将文件数据切割成数据包,通过管道(pipeline)方式依次写入多个DataNode,形成副本链。
- 读取:客户端从NameNode获取文件数据块的位置信息,然后直接与最近的DataNode建立连接读取数据,这种设计避免了中心节点的带宽瓶颈。
此架构完美体现了分布式系统设计的精髓:中心化管理元数据以实现高效调度,分布式存储数据以实现水平扩展和高吞吐。
三、HDFS Shell操作实战指南
HDFS提供了一套与Linux Shell命令风格相似的命令行接口,是管理员和用户进行日常文件管理的基础工具。所有命令均以 hdfs dfs 或 hadoop fs 为前缀。以下是一些核心操作示例:
- 文件系统基本操作
- 列出目录内容:
hdfs dfs -ls /user或hdfs dfs -ls hdfs://namenode:port/user
- 创建目录:
hdfs dfs -mkdir /user/testdata
- 上传本地文件到HDFS:
hdfs dfs -put localfile.txt /user/testdata/
- 从HDFS下载文件到本地:
hdfs dfs -get /user/testdata/file.txt ./
- 查看文件内容:
hdfs dfs -cat /user/testdata/file.txt或hdfs dfs -tail
- 复制/移动/删除文件:
hdfs dfs -cp /source /dest
hdfs dfs -mv /source /dest
hdfs dfs -rm /user/testdata/file.txt(删除文件)
hdfs dfs -rm -r /user/testdata(递归删除目录)
- 文件与权限管理
- 修改文件所属权:
hdfs dfs -chown user:group /path/to/file
- 修改文件权限:
hdfs dfs -chmod 755 /path/to/file(模式与Linux一致)
- 查看文件大小:
hdfs dfs -du -h /user(以人类可读格式显示)
- 高级与诊断命令
- 查看文件系统的使用情况:
hdfs dfs -df -h
- 统计文件/目录信息:
hdfs dfs -count /user
- 设置文件副本数:
hdfs dfs -setrep -w 5 /user/testdata/file.txt(将副本数改为5并等待完成)
- 平衡集群数据:
hdfs balancer(在DataNode间均衡数据块分布)
四、HDFS在计算机网络系统工程服务中的实践考量
将HDFS集成到企业网络系统工程中,需综合考虑以下方面:
- 网络规划:HDFS集群内部通信(如数据复制、心跳、数据块传输)会产生巨大的网络流量。工程实施时需要规划高带宽、低延迟的内部网络,并考虑机架感知(Rack Awareness)配置,将副本分布在不同的网络交换机或机架上,以提升容灾能力。
- 硬件选型与容量规划:DataNode的存储(HDD/SSD)、内存和CPU配置需根据工作负载(I/O密集型或计算密集型)进行权衡。NameNode需要足够的内存来承载文件系统元数据。
- 安全集成:在企业环境中,需集成Kerberos进行身份认证,并结合HDFS ACL(访问控制列表)及网络防火墙策略,构建多层次的数据安全防护体系。
- 监控与运维:需要部署监控系统(如Prometheus+Grafana,或Hadoop原生监控接口)对NameNode/DataNode健康状况、存储容量、RPC延迟等关键指标进行持续监控,并建立自动化运维流程。
- 与其他系统集成:HDFS通常作为底层存储,服务于Hive、HBase、Spark等上层计算框架。系统工程需要确保网络连通性、版本兼容性和性能调优。
五、
HDFS以其简洁而强大的主从架构,提供了处理海量数据的可靠存储方案。理解其NameNode与DataNode的协作机制、数据分块与多副本策略,是进行系统设计、性能调优和故障诊断的基础。而熟练运用HDFS Shell命令,则是日常数据管理和集群运维的必备技能。对于计算机网络系统工程服务而言,成功部署和维护HDFS集群,不仅需要扎实的理论知识,更需要在网络、硬件、安全和运维等多个工程维度上进行周密的规划和实践,从而为企业构建稳定、高效的大数据存储基石。
如若转载,请注明出处:http://www.suyongw.com/product/8.html
更新时间:2026-06-13 23:48:37